목차
1. EDA란
2. EDA에서 사용하는 주요 시각화 기법
3. 산점도 (Scatter Plot)
4. 히트맵 (Heatmap)
5. 페어플롯 (Pair Plot)
6. 카운트플롯 (Count Plot)
1. EDA란
EDA(Exploratory Data Analysis)는 데이터를 시각적으로 분석하여 데이터의 특징을 탐색하는 과정이다.
데이터 분석을 수행하기 전에 데이터를 다양한 관점에서 살펴보며 다음과 같은 요소를 확인한다.
- 데이터 분포
- 변수 간 관계
- 데이터 패턴
- 이상치
EDA를 통해 데이터의 특성을 이해하고, 이후 데이터 분석이나 머신러닝 모델링의 방향을 결정할 수 있다.
EDA에서는 다양한 시각화 기법을 활용하여 데이터를 직관적으로 분석한다.
2. EDA에서 사용하는 주요 시각화 기법
| 시각화 기법 | 목적 |
| 산점도 (Scatter Plot) | 두 변수 간 관계 확인 |
| 히트맵 (Heatmap) | 여러 변수 간 상관관계 분석 |
| 페어플롯 (Pair Plot) | 데이터셋 변수 간 관계 전체 확인 |
| 카운트플롯 (Count Plot) | 범주형 데이터 빈도 분석 |
| 박스플롯 (BoxPlot) | 데이터 분포 및 이상치 탐지 |
3. 산점도 (Scatter Plot)
산점도는 두 변수 간의 관계를 확인하는 그래프이다.
각 데이터는 점(point)으로 표현되며, 이를 통해 변수 간 상관관계를 확인할 수 있다.
예를 들어,
- 양의 관계 : 한 변수의 값이 증가할수록 다른 변수의 값도 증가하는 관계
- 음의 관계 : 한 변수의 값이 증가할수록 다른 변수의 값은 감소하는 관계
- 관계 없음 : 두 변수 간에 뚜렷한 관계가 없는 경우
등을 파악할 수 있다.
예제 1) 라이브러리 불러오기 + 한글 지원 설정
Matplotlib 기본 폰트가 한글을 지원하지 않기 때문에, 한글 폰트 설정도 같이 해준다.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
plt.rc('font', family='Malgun Gothic') # 한글 폰트 설정
plt.rcParams['axes.unicode_minus'] = False # 마이너스 깨짐 방지
예제 2) 예제 데이터 생성
공부 시간에 따라 시험 점수가 어떻게 변하는지 확인하기 위한 데이터를 생성한다.
data = pd.DataFrame({
'Study_Hours': [1, 2, 3, 4, 5, 6, 7, 8],
'Score': [50, 55, 65, 70, 75, 85, 90, 95]
})
print(data)
예제 2) 출력 결과
Study_Hours Score
0 1 50
1 2 55
2 3 65
3 4 70
4 5 75
5 6 85
6 7 90
7 8 95
예제 3) 산점도 확인
Seaborn에서는 scatterplot() 함수를 사용하여 산점도를 생성할 수 있다.
sns.scatterplot(
x='Study_Hours',
y='Score',
data=data
)
plt.title("공부 시간과 시험 점수의 관계")
plt.xlabel("공부 시간 (시간)")
plt.ylabel("시험 점수")
plt.show()
예제 3) 출력 결과

4. 히트맵 (Heatmap)
히트맵은 데이터 값을 색상으로 표현하는 그래프이다.
5. 페어플롯 (Pair Plot)
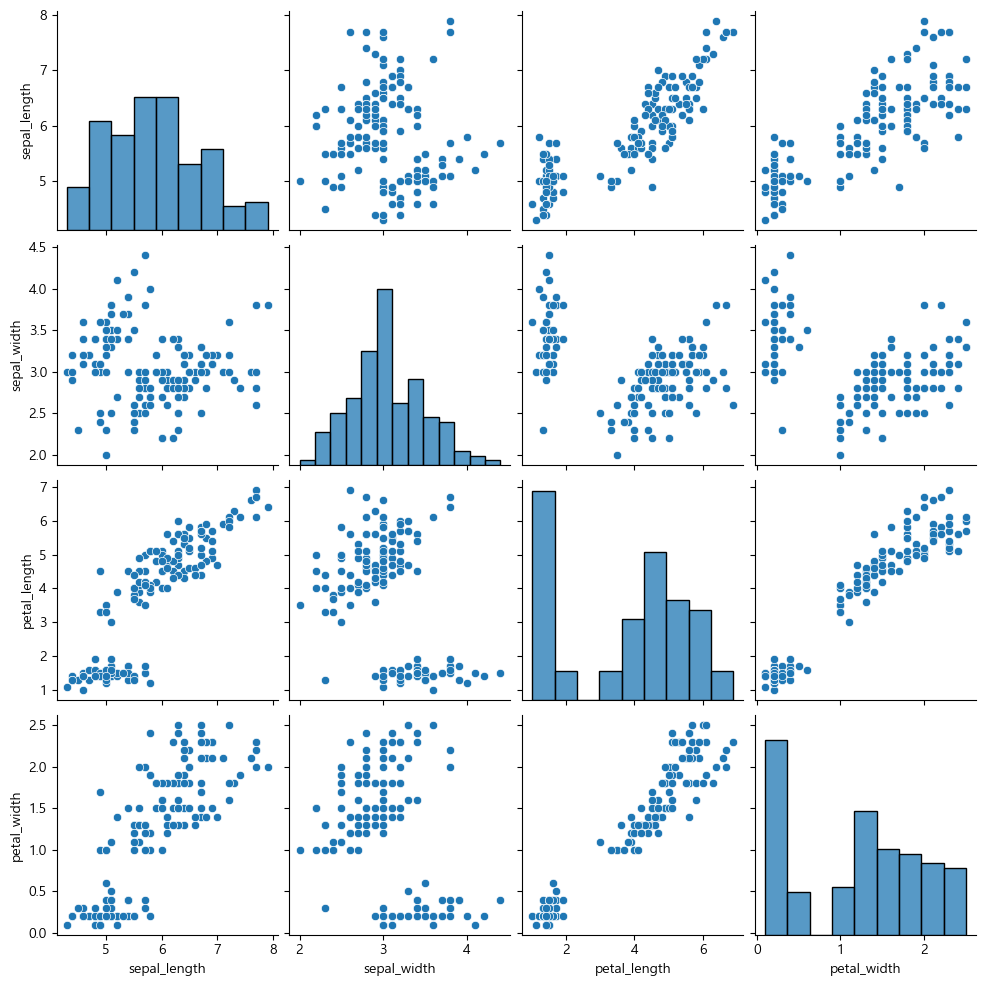
페어플롯은 데이터셋의 모든 변수 간 관계를 한 번에 확인할 수 있는 그래프이다.
각 변수 간 산점도를 생성하고, 대각선에는 변수의 분포를 표시한다.
데이터 탐색적 분석(EDA) 단계에서 변수 간 관계를 빠르게 확인할 때 유용하다.
예제 1) 라이브러리 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
예제 2) 예제 데이터 생성
Seaborn에서 제공하는 iris 데이터셋을 사용한다.
iris = sns.load_dataset("iris")
print(iris.head())
예제 2) 출력 결과
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
예제 3) 페이플롯 생성
Seaborn에서는 pairplot() 함수를 사용하여 페어플롯을 생성할 수 있다.
sns.pairplot(iris)
plt.show()
예제 3) 출력 결과
6. 카운트 플롯 (Count Plot)
카운트 플롯은 범주형 데이터의 빈도를 시각화하는 그래프이다.
각 범주(category)가 얼마나 자주 나타나는지를 막대 형태로 표현한다.
설문조사 결과나 범주형 데이터 분석에서 많이 사용된다.
예제 1) 라이브러리 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
예제 2) 예제 데이터 생성
학생들이 선호하는 프로그래밍 언어 데이터를 생성한다.
data = {
'Language': ['Python', 'Java', 'Python', 'C++', 'Python', 'Java', 'Python']
}
df = pd.DataFrame(data)
print(df)
예제 2) 출력 결과
Language
0 Python
1 Java
2 Python
3 C++
4 Python
5 Java
6 Python
예제 3) 카운트 플롯 생성
Seabron에서는 countplot() 함수를 사용하여 카운트 플롯을 생성할 수 있다.
sns.countplot(
x='Language',
data=df
)
plt.title("프로그래밍 언어 선호도")
plt.show()
예제 3) 출력 결과

'머신러닝&딥러닝' 카테고리의 다른 글
| 머신러닝 & 딥러닝 기초 17편 | 데이터 그룹화와 집계(Groupby, Pivot Table) (1) | 2026.03.16 |
|---|---|
| 머신러닝 & 딥러닝 기초 16편 | EDA(탐색적 데이터 분석) (0) | 2026.03.15 |
| 머신러닝 & 딥러닝 기초 14편 | Seaborn, 히트맵, 박스플롯, 바이올린플롯 (1) | 2026.03.14 |
| 머신러닝 & 딥러닝 기초 13편 | Matplotlib, 선 그래프, 막대 그래프, 히스토그램 (0) | 2026.03.14 |
| 머신러닝 & 딥러닝 기초 12편 | 정규분포, 왜도, 첨도 (0) | 2026.03.14 |