목차
1. Seaborn 이란
1-1 Seaborn 라이브러리 설치
2. 히트맵 (Heatmap)
3. 박스플롯 (Boxplot)
4. 바이올린플롯(Violin Plot)
1. Seaborn 이란
Seaborn은 통계 시각화를 위한 Python 라이브러리이다.
Matplotlib을 기반으로 만들어졌으며, pandas 데이터 구조와 쉽게 연동되어 사용할 수 있는 것이 특징이다.
Matplotlib보다 더 간결한 코드로 다양한 통계 그래프를 쉽게 생성할 수 있다.
- 히트맵(Heatmap)
- 박스플롯(Boxplot)
- 바이올린 플롯(Violin Plot)
- 산점도(Scatter Plot)
- 분포 그래프(Distribution Plot)
- 회귀 그래프(Regression Plot)
- 범주형 그래프(Categorical Plot)
Sebaron은 데이터의 분포, 관계, 통계적 특성을 시각적으로 분석할 때 매유 유용하다.
1-1 Seaborn 라이브러리 설치
Seaborn은 다음 명령어를 통해 설치할 수 있다.
pip install seaborn
2. 히트맵 (Heatmap)
히트맵은 데이터 값을 색상으로 표현하는 그래프이다.
데이터의 크기에 따라 색상이 달라지며, 이를 통해 데이터 패턴이나 관계를 직관적으로 확인할 수 있다.
특히, 상관관계 행렬(Correlation Matrix)을 시각화할 때 많이 사용된다.
예제 1) 라이브러리 불러오기
Seaborn 그래프는 Matplotlib과 함께 사용하는 경우가 많기 때문에 plt도 함께 import한다.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
예제 2) 데이터 생성
data = pd.DataFrame({
'Math':[80,90,85],
'English':[75,88,92],
'Science':[90,85,88]
})
print(data)
예제 2) 출력 결과
Math English Science
0 80 75 90
1 90 88 85
2 85 92 88
예제 3) 히트맵 생성 - heatmap()
Seabron에서는 heatmap() 함수를 사용하여 히트맵을 생성할 수 있다.
sns.heatmap(data)
plt.show()
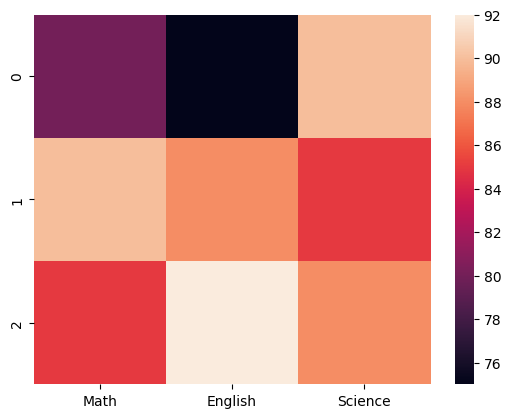
예제 3 출력 결과
데이터 값의 크기에 따라 색상이 달라지는 히트맵이 생성된다.
예제 4) 마스킹(mask) 생성
히트맵에서는 mask 옵션을 사용하여 특정 영역을 숨길 수 있다.
mask는 True/False 값으로 구성된 배열이며 다음과 같이 동작한다.
- True : 해당 셀을 가림
- False : 해당 셀을 표시
상관관계 행렬에서는 위쪽과 아래쪽 값이 동일하기 때문에, 상단 삼각형 영역을 숨기는 방식이 자주 사용된다.
이를 위해 NumPy의 triu()함수를 사용하여 상 삼각형 마스크를 생성할 수 있다.
import numpy as np
mask = np.triu(np.ones_like(data, dtype=bool))
- np.ones_like(data) : data와 동일 크기의 배열 생성
- dtype=bool : 배열 값을 True/False 형태로 생성
- np.triu() : 배열의 상단 삼각형 영역을 선택
즉, 위 코드는 히트맵이 상단 삼각형 영역을 숨기기 위한 마스크 배열을 생성하는 코드이다.
예제 5) mask를 적용한 히트맵 생성
mask를 사용하여 중복되는 영역을 제거하여 데이터 관계를 보다 직관적으로 확인할 수 있다.
sns.heatmap(
data,
mask=mask
)
plt.show()
예제 5) 출력 결과


예제 6) annot, cmap
annot 인자를 사용하여 각 셀에 데이터 값 표시 여부를 지정할 수 있다.
cmap 인자를 사용하여 히트맵 색상 스타일을 지정할 수 있다.
예를 들어, 'coolwarm'은 낮은 값은 파란색, 높은 값은 빨간색 계열로 표현하는 색상 스타일이다.
sns.heatmap(
data,
annot=True,
cmap='coolwarm',
mask=mask
)
plt.show()
예제 6) 출력 결과

3. 박스플롯 (Boxplot)
박스플롯은 데이터의 분포와 이상치를 확인할 수 있는 그래프이다.
박스플롯은 다음과 같은 정보를 보여준다.
- 중앙값(Median)
- 사분위수(Q1, Q3)
- 데이터 범위
- 이상치(Qutlier)
이를 통해 데이터 분포의 특징을 쉽게 확인할 수 있다.
박스플롯은 데이터의 분포와 이상치를 확인할 수 있어, 데이터 탐색(EDA, Exploratory Data Analysis) 단계에서 매우 자주 사용된다.
예제 1) 데이터 생성
Seabron은 예제용 데이터셋을 제공한다.
tips 데이터는 레스토랑 팁 데이터를 의미한다.
tips = sns.load_dataset("tips")
print(tips.head())
예제 1) 출력 결과
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
예제 2) 박스플롯 생성
Seabron에서는 boxplot() 함수를 사용하여 박스플롯을 생성할 수 있다.
sns.boxplot(
x='day',
y='total_bill',
data=tips
)
plt.show()
에제 2) 출력 결과
요일(day)에 따른 총 계산 금액(total_bill)의 분포를 확인할 수 있는 박스플롯이 생성된다.

- 박스 중앙선 : 중앙값(Median)
- 박스 위/아래 : 사분위수(Q1, Q3)
- 점 : 이상치
예제 3) palette 옵션
palette 옵션을 사용하면 그래프의 색상 스타일을 변경할 수 있다.
sns.boxplot(
x='day',
y='total_bill',
data=tips,
palette='pastel'
)
plt.show()
예제 3) 출력 결과

4. 바이올린 플롯(Volin Plot)
바이올린 플롯은 박스플롯과 분포 그래프를 결합한 형태의 그래프이다.
데이터의 분포 형태를 밀도(density)로 표현하며, 데이터가 어느 구간에 많이 분포하는지 확인할 수 있다.
박스플롯보다 데이터 분포를 더 자세하게 보여주는 특징이 있다.
바이올린 플롯은 데이터 분포의 형태를 직관적으로 확인할 수 있어, 데이터 탐색(EDA, Exploratory Data Analysis) 단계에서 자주 사용된다.
예제 1 ) 데이터 생성
Seabron은 예제용 데이터셋을 제공한다.
tips 데이터는 레스토랑 팁 데이터를 의미한다.
tips = sns.load_dataset("tips")
print(tips.head())
예제 1) 출력 결과
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
예제 2) 바이올린 플롯 생성
Seabron에서는 violinplot() 함수를 사용하여 바이올린 플롯을 생성할 수 있다.
어쩌구..추가 설명
sns.violinplot(
x='day',
y='total_bill',
data=tips
)
plt.show()
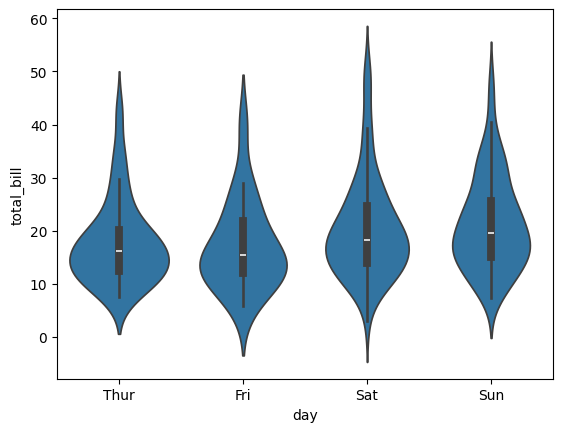
예제 2) 출력 결과
요일(day)에 따른 총 계산 금액(total_bill)의 분포 형태를 확인할 수 있는 바이올린 플롯이 생성된다.
그래프의 넓은 부분은 데이터가 많이 분포한 구간을 의미하며, 좁은 부분은 데이터가 적게 분포한 구간을 의미한다.
예제 3) palette 옵션
palette 옵션을 사용하면 그래프 색상 스타일을 변경할 수 있다.
sns.violinplot(
x='day',
y='total_bill',
data=tips,
palette='pastel'
)
plt.show()
예제 3) 출력 결과

예제 4) split 옵션
splilt 옵션을 사용하면 두 개의 분포를 하나의 바이올린 형태로 나누어 표현할 수 있다.
예를 들어, hue 옵션을 사용하여 두 번째 그룹화 변수를 추가한다.
그리고 split 옵션을 사용하여 두 그룹의 분포를 나누어준다.
sns.violinplot(
x='day',
y='total_bill',
hue='sex',
data=tips,
split=True,
palette='pastel'
)
plt.show()
예제 4) 출력 결과
각 요일(day)에 대해 남성과 여성의 총 계산 금액 분포가 하나의 바이올린 그래프 안에서 비교되어 표시된다.

'머신러닝&딥러닝' 카테고리의 다른 글
| 머신러닝 & 딥러닝 기초 16편 | EDA(탐색적 데이터 분석) (0) | 2026.03.15 |
|---|---|
| 머신러닝 & 딥러닝 기초 15편 | EDA(탐색적 데이터 분석)와 주요 시각화 기법 (1) | 2026.03.15 |
| 머신러닝 & 딥러닝 기초 13편 | Matplotlib, 선 그래프, 막대 그래프, 히스토그램 (0) | 2026.03.14 |
| 머신러닝 & 딥러닝 기초 12편 | 정규분포, 왜도, 첨도 (0) | 2026.03.14 |
| 머신러닝 & 딥러닝 기초 11편 | 분산, 표준편차, 사분위수 (0) | 2026.03.14 |